分布式任务调度
分布式任务调度
有时候猿粪到了,这边说说分布式任务调度的事.
先说说分布式任务调用系统的重要性吧.分布式任务调度,在企业中都是处于核心位置,而且处理的任务一般为一些应用系统的上游,比如大型金融系统的跑P,应用数据的ETL过程.
而目前开源领域对于分布式任务系统,各种五花八门,杂乱纷呈.
在某些应用内,框架的作用其实并不大,某些情况还不如我写的qilu-task来的灵活实在.我也曾经见过某大行的分布式任务,集成各种中间件,最后做了个寂寞.
那如果我们要定制一个分布式任务调度系统,应该如何来实现呢?
抽象分析
除了监控界面以外,还有哪些东西需要考虑的呢??
我们要从分布式任务的应用场景聊起.分布式任务调用目前最主要的场景
- 全司级别的任务调度,就是整个公司就我一个调度控制,控制全公司的调度
- ETL
在这2个场景中,我认为最重要的就是"任务依赖".
那这个任务依赖为什么重要呢??
- 任务依赖是数据准确的前提
- 任务依赖是数据转移过程中的最大保障
假设我们的任务场景前提是通过FTP文件获取外系统数据,如果5分钟时间到了,当前任务对应的文件A01没有产生,后续的任务要不要做??站在现在这个点上,回答肯定是不要,因为无论做多少容错,只要执行后续任务,都是错.
如果5分钟后,业务系统的错误没有解决,后面一个任务已经触发,后面任务对应的A02文件还是没有生成,后续的任务怎么办???如果我们等了30分钟以后,才发现业务系统有问题,解决问题花了2小时,中间一共会产生25个任务和文件,系统要怎么做才能兼容???
上述的问题,在金融领域记录每日发生额的情况下,尤为重要.特别是账务数据,都是随着上一个周期的值来计算下一个周期的数据.
而在其他的场景里面,各种配置信息,比如节假日表(只有别人依赖它,它不会依赖别人),这种数据的迁移和业务数据的迁移策略会不一样,全表同步,如果是5分钟执行,错了就错了,下个5分钟数据还是会自动补全.
再接近现实一点的场景,还有不同周期的依赖,比如银行内的账务跑批是一天一跑,而小规模的业务数据是5分钟一次,对于不同周期的任务,如果今天的账务跑批没跑完,业务数据的批能不能停下来???跑完了,能再跟上么????
除了上面的依赖关系以外,还有各种隐藏任务.
这边列出部分场景,做个简单说明.
- 需要考虑到单节点执行数据量过大,导致任务流程被单节点卡住,需要支持任务分片操作.
- 正常的任务流程,一定需要引入fork和join,加入fork和join就意味着当前的流程在执行过程中同时存在多个存活的节点.那么问题来了,是否允许有多个结束节点??如果有多个结束节点,如何判断任务结束???
- 在复杂场景下,应该考虑任务自己判断是否满足执行条件,如果不满足执行条件,需要等待,并接受通知执行.而通知的发起往往是另外的任务.需要支持任务通知.
核心逻辑
开发一套全司级别的分布式任务平台,需要考虑的东西太多了,没有调研,完全cover不住.简单做点删减.
- 不考虑执行方式,执行方式影响到软件集成情况,又是一个很大的话题.
- 只考虑内部流程处理逻辑.核心的是流程处理逻辑,任何小范围的变动都无法撼动流程内部的核心逻辑.
有了前提,所以核心模型就能出来.
流程配置模型 
因为要支持fork/join,所以一个节点会有多个入口,使用节点线路把节点关系给串联起来.这边要额外说下节点依赖.
解决流程依赖
节点依赖,可以看成流程依赖的一个扩展,只不过切入点放在了每个节点上.流程依赖在执行上,都是一个具体的流程实例依赖哪些个流程实例,在配置模型上可以不用体现.
在配置模型上体现的想法,是想在图形化的配置过程中,可以看到一个流程依赖哪些流程.放在配置上还有一个好处,就是可以简化创建流程实例时候对依赖信息的传递.
在流程配置上有一个标识取值方式,在节点依赖配置上,有一个取时方式,这2个属性可以通过一些定义来满足任务依赖.
在任何一个任务提交的时候,都应该传入唯一标识,可以规定这个唯一标识不能传入,只能通过(日期+标识取值)产生,比如每日的日切的一个流程,标识取值方式=日期,唯一标识就可以是20000101,是一个到具体日期的字符串用来标识到日.
提示
所以在这边可以定义出整个系统的创建流程的方法定义
/**
* flowCode,用于绑定流程配置
* param,流程参数,用于各种流程参数的计算
* dependencyInfo,依赖信息
*/
FlowInstance create(String flowCode ,String 唯一标识, Map<String , Object> param , Set<flowCode , 依赖任务的唯一标识> dependencyInfo);
FlowInstance create(String flowCode , Map<String , Object> param , Set<flowCode , 依赖任务的唯一标识> dependencyInfo);一个5分钟的任务,可以生成一个唯一标识为200001011005,说明是一个具体的5分钟的标识.上面的接口定义不再需要发起方传入唯一标识,而是通过绑定flowCode,通过流程配置上的标识取值方式,统一得到一个具体的流程编号.在一天内,有相同的flowCode被调用,系统会不允许创建一个流程,做的好一点,也可以返回已经创建的流程实例. 标识取值方式,就变成怎么对日期取唯一标识的取值策略,取值范围可以是
- 切日
- 切小时
- 切30分钟
- 切10分钟
- 切5分钟
- 切分钟
如果所有的任务标识都是通过日期相关来产生,那么我们可以让接口中的dependencyInfo传入的信息作为较高的优先级,默认生成依赖流程实例的标识号,如果传入了dependencyInfo,就使用传入信息作为依赖信息.
取时方式就是在没有传入依赖信息,但是已经配置依赖时候,对于依赖流程的唯一标识的获取方式.本质上是传给唯一标识取值的一个时间范围,可以取值的范围有
- 昨日
- 上个小时
- 下个小时
等等
流程执行模型 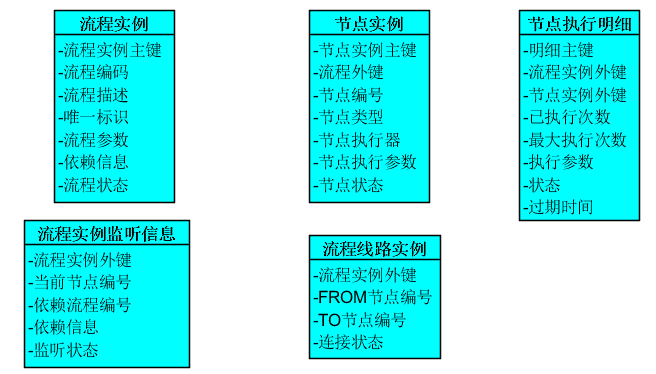
fork/join实现
流程在创建初始,就直接从流程线路配置中获取流程的各种连线,插入流程线路实例,状态为"未检查".
在流程节点执行结束的时候,需要做如下操作.
- 修改当前节点实例,节点执行明细的状态.
- 判断当前节点的出口连接,设置连接状态.
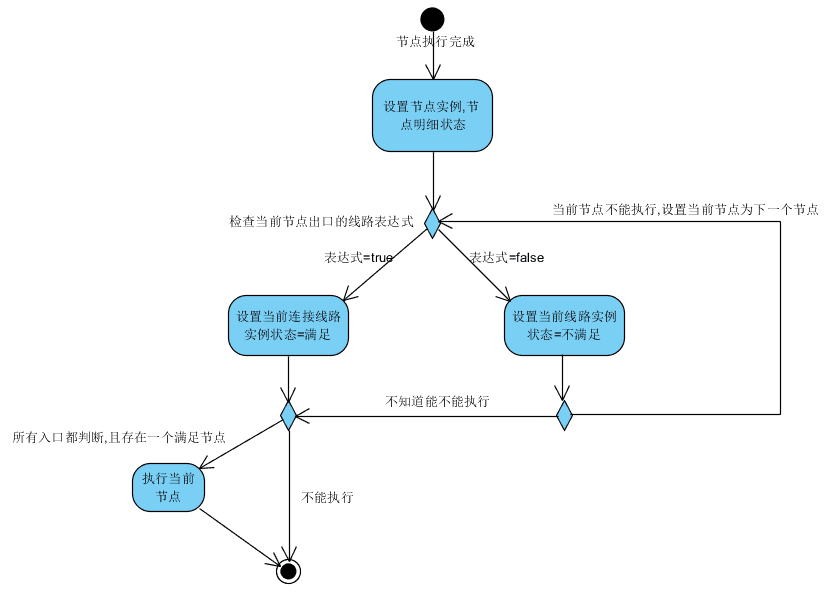 如果出口条件满足,则修改流程线路实例连接状态为"满足",如果出口条件不满足,修改流程线路实例连接状态状态为"不满足".如果流程线路实例连接状态状态="不满足",需要再次判断当前节点有多少个入口,如果除开当前连接,已经不存在另外的"未检查"线路,遍历当前节点下的所有节点,设置下面所有节点的流程线路实例连接状态状态为"不满足".
如果出口条件满足,则修改流程线路实例连接状态为"满足",如果出口条件不满足,修改流程线路实例连接状态状态为"不满足".如果流程线路实例连接状态状态="不满足",需要再次判断当前节点有多少个入口,如果除开当前连接,已经不存在另外的"未检查"线路,遍历当前节点下的所有节点,设置下面所有节点的流程线路实例连接状态状态为"不满足".
- 判断满足节点执行条件的节点,开始执行节点.
提示
fork的时候,会分成多个执行线程去执行节点.
join的时候,一个节点会存在多个入口线路.线路状态的修改,在节点执行完成以后,能保证后续的节点在fork阶段就已经能判断一个节点线路是否有效了.
因为存在路由边的缘故,线路的状态只是代表当前的线路是否有效,如果线路被判断为"不满足",则相当于在图形上去掉了这条线路.
一个节点,只要有一个入口执行,当前节点就会执行.如果一个入口都没有,当前节点就不会有线程执行,所以只能在父节点执行的时候,判断子节点是否有多个入口,如果没有多个入口,就直接设置当前的线路.
如何判断一个流程结束?
为了页面上展示方便,所以在流程配置模型里面引入了节点类型,节点类型一般有3个取值,开始节点,一般节点和结束节点.在引入fork/join的机制下,流程内部的节点不一定存在唯一的结束节点,很大概率会存在多个结束节点.就像上图展示的那种UML中的活动图那样.
对于流程来说,流程执行完成,就意味着所有节点都已经执行完了,但是要再执行过程中去判断当前的流程已经结束,而且是在多个线程中分别执行的节点来判断当前的流程是否已经结束,这是很困难的.
介于上面讲fork/join实现的时候,讲到了join节点的等待问题,其实如何判断一个流程结束可以看成,所有的结束节点都默认指向一个真正的结束节点,而真正的结束节点,在配置中不存在,可以再运行的时候生成线路实例.在执行这个真正结束的节点,就变更当前的流程实例.
不该有的结束
不多说了.
如果配置使用xml,执行使用DB存储,这个流程核心就能做成springBatch一样的框架.
如果使用sdk执行handler,流程核心做平台化处理,加入通讯模块,就能做成XXL-JOB类似的调度工具.
但是无论是扩展性,还是易用性,包括容错性,都能上一个台阶.
如果不考虑分片功能,配置使用xml,执行存储可以放在redis,执行使用线程池,这个核心还可以作为复杂业务的调度框架,只不过,所有的执行都是异步,没有事务管控.