mybatis增强(qilu-mybatis)介绍
mybatis增强(qilu-mybatis)介绍
在开源领域已经存在pageHelper,mybatis-plus的情况下,为啥还要开发qilu-mybatis????
主要是我有偏见,我们认为在pageHelper和mybatis-plus之外,还有一种更好用的mybatis的使用方式.这种方式在于在mybatis-generator-tool自动生成的各种操作太好用了,以至于我认为可以抛弃pageHelper和mybatis-plus带来的便利,而一定要集成mybatis-generator的生成类的方式来使用mybatis.
qilu-mybaits主要特性
- 支持不同数据库
- 特别是常见的分页,主键策略都存在很大的差异
- mybatis-generator的集成
- mybatis-generator是一个很强大的代码生成器,特别是中间的Mapper和配置文件的生成,使用比较爽,爽到需要替换pageHelper或者mybatis-plus
代码集成
qilu-mybatis的maven依赖
<dependency>
<groupId>com.9istock.base</groupId>
<artifactId>qilu-mybatis</artifactId>
<version>最新版本</version>
</dependency>qilu-generator的maven依赖
<dependency>
<groupId>com.9istock.base</groupId>
<artifactId>qilu-generator</artifactId>
<version>最新版本</version>
<scope>test</scope>
</dependency>使用
spring配置
在spring的配置文件中增加mybatis的扫描和qilu-mybatis的bean
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.istock.union.user.dao" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"></property>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<!-- 自动扫描mapping.xml文件 -->
<property name="mapperLocations" value="classpath:unionUser/**/*.xml"></property>
<property name="plugins">
<list>
<ref bean="pageInterceptor"/>
</list>
</property>
</bean>
<!--拦截器的注入-->
<bean id="pageInterceptor" class="com.istock.base.mybatis.interceptor.PageInterceptor">
<property name="commonExecutor" ref="commonExecutor">
</property>
</bean>
<bean id="commonExecutor" class="com.istock.base.mybatis.executor.CommonExecutor">
<!-- 可以不指定,常见的数据库可以自动识别,包含MYSQL,MSSQL,DB2,ORACLE -->
<!-- <property name="dialect">
<bean class="com.istock.base.mybatis.dialect.MysqlDialect"></bean>
</property> -->
<!--主键生成策略-->
<property name="keyType" value="MEM18"/>
<!--不同的表可以使用不同的组件策略-->
<!-- <property name="tableMap">
<map>
<entry key="AUTH_AUDIT_LOG">
<value>SEQ</value>
</entry>
<entry key="TEST_SENVON_INFO">
<value>MEM</value>
</entry>
</map>
</property> -->
</bean>
<!--组件策略注入-->
<bean name="strategyService" class="com.istock.base.mybatis.strategy.StrategyService" factory-method="getInstance">
<property name="strategySet">
<set>
<!--依赖数据库的sequence策略生成主键,支持Oracle,DB2,SqlServer-->
<bean class="com.istock.base.mybatis.strategy.SequenceIdStrategy">
<property name="dataSource" ref="dataSource"></property>
<property name="sequenceNumber" value="30"></property>
</bean>
<!--基于snowflake的内存模式下的主键生成,支持所有数据库-->
<bean class="com.istock.base.mybatis.strategy.SnowFlackStrategy">
</bean>
</set>
</property>
</bean>在CommonExecutor中,我们可以配置不同的数据库方言,一种支持4种数据库方言
- Mysql: com.istock.base.mybatis.dialect.MysqlDialect
- Oracle: com.istock.base.mybatis.dialect.OracleDialect
- DB2: com.istock.base.mybatis.dialect.DB2Dialect
- MSSQL: com.istock.base.mybatis.dialect.MSSqlDialect
如果commonExecutor不配置数据库方言,系统就会在启动的时候默认使用数据库产品进行设置
在commonExecutor中,可以配置不同的表使用不同的主键策略,主键策略有二种类型
- MEM:使用内存生成主键(推荐使用)
- MEM18:使用内存生成18位数字(传统的snowflake有时候会生成19位数字)(推荐使用)
- SEQ:使用数据库的sequence功能生成主键
StrategyService,是主键策略的自定义,可以支持二次开发,需要实现com.istock.base.mybatis.strategy.IdStrategy接口
在使用qilu-mybatis进行batch,insert操作时,为了减少数据库的访问会生成批量的获取id,在这种模式下,无法支持自增长主键的生成.
在使用修改后的qilu-generator的基础上,正常生成mapper和pojo类
代码自动生成
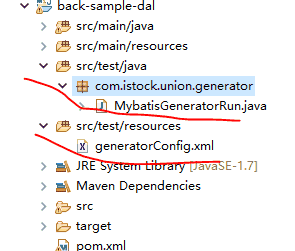 在dal子项目中,test/resources/generatorConfig.xml就是生成的配置文件,而test/java里面的MybatisGeneratorRun.java则是运行类.运行这个类,会自动加载generatorConfig.xml中的配置,按照配置生成对应的java映射.
在dal子项目中,test/resources/generatorConfig.xml就是生成的配置文件,而test/java里面的MybatisGeneratorRun.java则是运行类.运行这个类,会自动加载generatorConfig.xml中的配置,按照配置生成对应的java映射.
生成工具的maven依赖
<dependency>
<groupId>com.9istock.base</groupId>
<artifactId>qilu-generator</artifactId>
<version>1.0.0</version>
</dependency>配置
<context id="OracleTables" targetRuntime="MyBatis3">
<plugin type="org.mybatis.generator.plugins.ToStringPlugin"></plugin>
<plugin type="org.mybatis.generator.plugins.EqualsHashCodePlugin"></plugin>
<plugin type="com.istock.generator.plugin.TopSerializablePlugin"></plugin>
<plugin type="com.istock.generator.plugin.SqlMapUnMergePlugin"></plugin>
<!-- DAO的生成,带有分页标识 -->
<!-- 生成mybatis -->
<plugin type="com.istock.generator.plugin.MybatisPagePlugin">
<property name="pageClass" value="com.istock.base.common.api.model.PageInfo"/>
</plugin>
<commentGenerator type="com.istock.generator.plugin.DBCommentGenerator">
<property name="suppressAllComments" value="true" />
</commentGenerator>
<!-- <jdbcConnection driverClass="oracle.jdbc.driver.OracleDriver" connectionURL="jdbc:oracle:thin:@101.200.228.39:1521:vfinance"
userId="test" password="123">
<property name="remarksReporting" value="true" />
</jdbcConnection> -->
<jdbcConnection driverClass="org.gjt.mm.mysql.Driver" connectionURL="jdbc:mysql://senvon.vm:3306/new-user?useUnicode=true&characterEncoding=UTF-8"
userId="root" password="123">
<property name="remarksReporting" value="true" />
</jdbcConnection>
<!-- POJO类生成配置 -->
<javaModelGenerator targetPackage="com.istock.union.user.model" targetProject="../back-sample-dal/src/main/java">
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!-- SqlMap文件生成配置 -->
<sqlMapGenerator targetPackage="unionUser" targetProject="../back-sample-dal/src/main/resources">
</sqlMapGenerator>
<!-- Dao生成配置 -->
<javaClientGenerator type="XMLMAPPER" targetPackage="com.istock.union.user.dao" targetProject="../back-sample-dal/src/main/java">
</javaClientGenerator>
<!-- 数据库表 -->
<table tableName="SYS_TENANT_INFO" domainObjectName="TenantInfo">
<generatedKey column="ID" sqlStatement="GENID('SYS_TENANT_INFO')" />
</table>运行MybatisGeneratorRun,来得到生成的代码.可以在user-dal/test/...下找到
注意
- 被生成的表SYS_TENANT_INFO中,一定要在数据库层面设置单字段主键.如果表不存在主键,则不会生成SelectByKey,updateByKey的一些操作,如果表中存在联合主键,就会生成额外的主键查询.
- generatedKey的sqlStatement,这个字段是一个表达式,qilu-mybatis通过表达式的处理,加载不同的主键策略.这边可以配置为比如Date + 'TB'+ GENID ( 'TEST_TASK_INFO' ) 这就代表使用当前的日期+TB+主键策略的数字组成一个主键.
- 所有自动生成的代码不是拿来修改的,而是拿来直接使用的,请不要修改任何自动生成的代码,否则数据库变更的时候,修改的那些代码将会被覆盖
- 本工具只是对原本的mybatis-generator-tool的增强,在生成mapper,Example的时候,增加了部分内容,原本mybatis-generator-tool的配置依旧生效.
使用范例
分页查询
AuditLogExample example = new AuditLogExample();
AuditLogExample.Criteria criteria = example.createCriteria();
criteria.andSrcIdLike("%2017%");
List<Long> idList = new ArrayList<Long>();
idList.add(10L);
idList.add(11L);
criteria.andIdIn(idList);
PageInfo page = new PageInfo();
List<AuditLog> logList = auditLogMapper.selectByExample(example, page);top查询
使用分页的api,不再进行count统计
AuditLogExample example = new AuditLogExample();
AuditLogExample.Criteria criteria = example.createCriteria();
criteria.andSrcIdLike("%2017%");
PageInfo page = new PageInfo();
page.setNeedCount(false);
List<AuditLog> logList = auditLogMapper.selectByExample(example, page);
logger.debug("pageNo:{} , pageTotal:{} " ,new Object[] { page.getLimit(),page.getTotalPage()});
logger.debug("logListSize:{}",logList.size());乐观锁更新
AuditLogExample example = new AuditLogExample();
AuditLogExample.Criteria criteria = example.createCriteria();
criteria.andIdEqualTo(10L);
criteria.andOrgIdGreaterThanOrEqualTo("123");
AuditLog updateRecord = new AuditLog();
updateRecord.setIp("senvon's ip");
auditLogMapper.updateByExampleSelective(updateRecord, example);带条件的批量更新,生成的代码提供3种更新,updatebyExample,updateByKey和updateBySelective
- updatebyExample,如果传入字段为空,则插入null
- UpdateByKey,通过主键更新
- UpdateBySelective,如果传入字段为空,则不生成该字段的更新语句
批量处理
@Autowired
private SqlSessionFactoryBean sessionFactory;
@Test
@Transactional
public void test1() throws Exception{
//当前的session的connection会被spring的DataSourceHolder进行管理,拿到的connection就是transactionManager的connection
//所以,这边不需要对事务进行操作
SqlSession session = sessionFactory.getObject().openSession(ExecutorType.BATCH);
AuditLogMapper auditLogMapper = session.getMapper(AuditLogMapper.class);
for(int i =0 ; i<100 ; i++){
AuditLog auditLog = new AuditLog();
auditLog.setIp("senvon's ip"+i);
auditLog.setOrgId("org ip "+i);
auditLog.setReqParams("params "+i);
auditLog.setRootOrgId("root--"+i);
auditLog.setSrcId("srcId"+i);
auditLog.setStatus("s");
auditLog.setUserId("uid"+i);
auditLog.setVisitDate(new Date());
auditLog.setVisitUrl("url"+i);
auditLogMapper.insertSelective(auditLog);
}
session.flushStatements();
session.close();
}在中间可以使用多个mapper的处理.
警告
如果批量处理里面出现多个mapper的调用,是不影响批处理的执行,但是会影响具体sql的执行顺序,mybatis会把相同的sql放在一个请求里面提交
如果要使用批量,请一定要使用
@Transactional注解,这个注解会帮你申请连接,归还连接.
如果在多线程环境下同时不使用spring的事务管理,一定要显示调用
session.commit()和session.close(),请一定要将session.close()的调用放到finally代码块中
模板表/分表的操作
在开发应用的过程中,难免会使用到模板表,针对某一个特定的值,访问特定的表,比如XX_TABLE_NAME_2020,XX_TABLE_NAME_2019.很明显,这种示例就是按照年份进行的分表操作,表的字段都是一样的.
qiluMybatis的代码自动生成,让自动生成的mapper和example,直接使用于模板表,提供更加便捷的操作.
假设模板表是TEST_MODEL_TABLE_2021,我们只需要做如下操作:
- 在测试数据库新建表,表名为
TEST_MODEL_TABLE_$CREATE_YEAR$,一定要在物理的数据库上新建表,且表名中的模板信息,要使用$$进行闭包处理.生产库上无须创建.分表键需要在表字段中存在,否则insert操作会失败. - 正常使用generate.xml配置,生成mapper,配置类似这样

- 在使用example的时候,记得对
createYear字段进行设置,一定要设置该字段,否则执行会报错
使用正常的example进行操作
ModelTable update = new ModelTable();
update.setAge(0);
update.setCreateYear(2021);
update.setName("aaa");
update.setId(lastId);
mapper.updateByPrimaryKey(update);
ModelTableExample example = new ModelTableExample();
ModelTableExample.Criteria criteria = example.createCriteria();
example.setCreateYear("2021");
criteria.andNameLike("%senvon%");
//每页取2条
PageInfo pageInfo = new PageInfo(2);
List<ModelTable> tableList = mapper.selectByExample(example, pageInfo);如果上述createYear=2021,最终生成的sql访问的表为TEST_MODEL_TABLE_2021
自定义SQL
自定义sql使用分页
生成工具的理念,不要动生成的东西,而不是修改
自定义的sql,Mapper接口定义在dao.ext中,Sql文件创建在mapper/ext中
 在自定义sql下的分页查询
在自定义sql下的分页查询
public List<UserInfoVO> selectUserListByPage(Map<String , Object> param , PageInfo<UserInfoVO> page);sql语句如下
<select id="selectUserListByPage" resultMap="BaseResultMap" parameterType="java.util.HashMap">
SELECT
U.ID, U.TENANT_CODE, U.DEPT_CODE, U.LOGIN_NAME, U.USER_NAME, U.EMAIL, U.PHONE_NUMBER, U.SEX,
U.PASSWORD, U.SALT, U.STATUS, U.CREATE_BY, U.CREATE_TIME, U.UPDATE_BY, U.UPDATE_TIME,
U.REMARK,T.TENANT_NAME
, D.DEPT_NAME
FROM SYS_USER_INFO U LEFT JOIN SYS_DEPT_INFO D ON U.DEPT_CODE = D.DEPT_CODE
LEFT JOIN SYS_TENANT_INFO T ON U.TENANT_CODE = T.TENANT_CODE
WHERE LOGIN_NAME != 'admin'
<trim prefix="AND">
<if test="loginName != null and loginName != ''">
U.LOGIN_NAME LIKE #{loginName}
</if>
<if test="status != null">
U.STATUS = #{status}
</if>
<if test="phoneNumber != null and phoneNumber != ''">
U.PHONE_NUMBER LIKE #{phoneNumber}
</if>
<if test="beginTime != null"><!-- 开始时间检索 -->
U.CREATE_TIME >= #{beginTime}
</if>
<if test="endTime != null"><!-- 结束时间检索 -->
U.CREATE_TIME <= #{endTime}
</if>
<if test="deptCode != null and deptCode.size()>0">
U.DEPT_CODE IN
<foreach collection="deptCode" index="index" item="item" open="(" separator="," close=")">
#{item}
</foreach>
</if>
</trim>
<if test="orderByClause != null">
ORDER BY ${orderByClause}
</if>
</select>自定义的分页查询声明,接口参数中,请包含PageInfo对象,在调用过程中,不需要使用任何分页的语句,自动拦截的时候会自动拼接上配置数据库方言的分页.
模板表/分表的联合查询
一旦分表以后,有时候需要对分表进行联合操作.下面的方法是最简单的实现分表联合查询的方法.
- 新建Example,继承之前自动生成的example(自动生成的理念是,自动生成的代码不动).
public class ExtModelTableExample extends ModelTableExample {
private List<String> createYearList = new ArrayList<String>();
public List<String> getCreateYearList() {
return createYearList;
}
public void setCreateYearList(List<String> createYearList) {
this.createYearList = createYearList;
}
}- 按照以下方式,实现sql的配置
<select id="findUnionTable" parameterType="com.istock.mybatis.user.model.ExtModelTableExample" resultMap="com.istock.mybatis.user.dao.ModelTableMapper.BaseResultMap">
<foreach collection="createYearList" item="createYearList" separator=" union all ">
<trim prefix="(" suffix=")">
select
<if test="distinct">
distinct
</if>
<include refid="com.istock.mybatis.user.dao.ModelTableMapper.Base_Column_List" />
from TEST_MODEL_TABLE_${createYearList}
<if test="_parameter != null">
<include refid="com.istock.mybatis.user.dao.ModelTableMapper.Example_Where_Clause" />
</if>
</trim>
</foreach>
<if test="orderByClause != null">
order by ${orderByClause}
</if>
</select>- 代码调用
ExtModelTableExample example = new ExtModelTableExample();
example.getCreateYearList().add("2021");
example.getCreateYearList().add("2020");
ModelTableExample.Criteria criteria = example.createCriteria();
criteria.andNameLike("%senvon%");
example.setOrderByClause("CREATE_YEAR DESC");
PageInfo pageInfo = new PageInfo(2);
List<ModelTable> tableList = extMapper.findUnionTable(example, pageInfo);生成的sql语句如下
( select ID, NAME, AGE, CREATE_YEAR from TEST_MODEL_TABLE_2021 WHERE ( NAME like ? ) ) union all ( select ID, NAME, AGE, CREATE_YEAR from TEST_MODEL_TABLE_2020 WHERE ( NAME like ? ) ) order by CREATE_YEAR DESC limit 0,2
非常规数据库操作
事务不生效的排查
- 检查spring配置文件,是否有
<tx:annotation-driven />的配置 - 扫描参与事务的类的时候,需要使用listener的方式加载,不能使用dispatcher-servlet的方式加载.这是2种不同的spring的配置加载方式,会出现相互覆盖的情形,一般配置dispatcher-serlvet不扫描service类,只扫描controller类.
- 检查抛出的异常,spring只会对runtimeException的异常做回滚处理,一般的Exception没有特殊声明,不会回滚
- 方法内部的调用,不会触发事务控制.一个类里面,有没有事务的methodA方法,调用有事务的methodB方法,methodB上的事务,不会生效.spring的事务是使用拦截器实现的,在实现拦截器是使用动态代理实现的,一个类的内部调用,不会触发动态代理.
方法内部的事务控制
常见推荐的事务操作,是在方法上,增加@Transactional的注解,这种级别的注解可以有效解决80%以上的业务问题,而且很方便.但是针对有些业务场景,正常的事务需要细化到方法内部,手动控制事务的提交和回滚.
@Autowired
private TransactionTemplate template;
@Autowired
private OrgUserDAO orgUserDao;
public OrgUser updateOrg(final String key){
//do something not in the transaction
return template.execute(new TransactionCallback<OrgUser>(){
@Override
public OrgUser doInTransaction(TransactionStatus status) {
try{
OrgUser user = new OrgUser();
user.setId(key);
user.setUserName("senvonTest");
orgUserDao.updateByPrimaryKeySelective(user);
return orgUserDao.selectByPrimaryKey(key);
}catch(Exception e){
status.setRollbackOnly();
e.printStackTrace();
}
return null;
}
});
//do something not in the transaction
}直接使用DataSource
Spring管理了所有的数据源,在大部分的业务场景里面,数据源对于应用系统来说,是一个相对静态的资源.在部分业务场景里面,数据源是一个动态的资源,在部署配置的时候,无法将数据源配置到系统里面 在spring的管理的数据源下面,不允许出现手动DataSource.getConnection()的操作,也不允许出现conn.close()操作,手动操作数据源,会引发数据源的衰竭,一个被关闭的数据源,spring没有保证一定是连接状态,在应用程序申请数据源的过程中,如果没有控制好,就会出现数据源返回一个已经关闭的连接,造成系统各种异常 如果出现这种情形,请使用spring提供的JdbcTemplate或者NamedParameterJdbcTemplate来实现数据库操作.
//直接注入数据源
@Autowired
private DataSource dataSource;
public List<OrgUser> findUser(String name){
String sql = "SELECT * FROM TB_ORG_USER WHERE USER_NAME LIKE :userName";
//使用JDBCTemplate操作数据源
NamedParameterJdbcTemplate template = new NamedParameterJdbcTemplate(dataSource);
Map<String , Object> paramMap = new HashMap<String , Object>();
paramMap.put("userName", name);
return template.query(sql, paramMap, new RowMapper<OrgUser>() {
@Override
public OrgUser mapRow(ResultSet rs, int rowNum) throws SQLException {
OrgUser user = new OrgUser();
user.setDeptCode(rs.getString("DEPT_CODE"));
user.setId(rs.getString("ID"));
user.setIdCode(rs.getString("ID_CODE"));
user.setPassword(rs.getString("PASSWORD"));
user.setRemark(rs.getString("REMARK"));
return user;
}
});
}替代存储过程
无论是数据库上的function,procedure还是job,理论上都是属于数据库工具,开发人员不应该触碰这类工具
数据库工具最大的好处是直接在数据库上操作,避免大的数据量的交互.但是会占据数据库的CPU,而数据库的CPU在整个系统群里面,是最珍贵的,没有之一.
比如有这么一个场景,日终给活期账户计算利息.
一个很简单的操作,会因为活期账户的数量成为难题,如果活期账户在1W以内,随便操作. 但是如果活期账户数量达到100W+,事情就会变得难办.要计算利息,必须先把记录从数据库中加载到内存,再计算.
所以,为了避免大量数据的操作,就会考虑使用游标,这个也就是一般活期计算利息使用存储过程的一个原因.
下面这种处理方式,既能解决数据量大的问题,又能解决性能的问题
@Autowired
private DataSource dataSource;
public void test(){
String sql = "SELECT * FROM TB_ORG_USER";
JdbcTemplate template = new JdbcTemplate();
template.query(sql, new ResultSetExtractor<Object>(){
@Override
public Object extractData(ResultSet rs) throws SQLException,DataAccessException {
//设置resultSet获取数据的缓存
rs.setFetchSize(10000);
List<OrgUser> userList = new ArrayList<OrgUser>();
while(rs.next()){
OrgUser user = new OrgUser();
user.setDeptCode(rs.getString("DEPT_CODE"));
user.setId(rs.getString("ID"));
user.setIdCode(rs.getString("ID_CODE"));
user.setPassword(rs.getString("PASSWORD"));
user.setRemark(rs.getString("REMARK"));
userList.add(user);
if(userList.size()>10000){
//启动线程,执行计算
// new Thread();
userList.clear();
}
}
//rs.next退出,userList会有遗留的数据没有处理
if(userList.size()>10000){
//启动线程,执行计算
// new Thread();
userList.clear();
}
return null;
}
});
}解决的原理很简单,JDBC中的ResultSet,在数据库层面的实现就是游标,为了使用游标,而是用存储过程,是一种不明智的选择.更多的应该在应用层面解决这个问题,而不是在数据库. 这种方式,对比存储过程的处理方式,唯一不好的,是会消耗数据库的网络IO,但是可以减少DB上的CPU压力,带来的是应用的大批量的多线程处理,总体来说利大于弊,收益更大.